
Vaya debate que se genera en las comunidades cuando se habla acerca de los archivos llms.txt. Las posiciones están muy confrontadas: por un lado, tenemos a los defensores que argumentan su potencial; y por otro, a quienes tajantemente aseguran que son archivos carentes de valor y sin ninguna utilidad práctica.
Por mi parte, me encuentro en una posición intermedia. Es cierto que, de momento, no le veo mucha aplicación directa, pero también tengo muy claro que las reglas del juego pueden cambiar rápidamente. Por ello, sigo muy de cerca la evolución de este tema.
Recordemos que el archivo llms.txt fue propuesto como una guía para que los LLMs rastreen y comprendan el contenido de los sitios web. Ha generado un considerable debate en la comunidad tecnológica, y su implementación y utilidad siguen siendo un tema de discusión, especialmente debido a las posturas divergentes de los gigantes de la IA.
La Postura de Google: «Ningún Sistema de IA lo Usa Actualmente»
John Mueller de Google ha dejado claro que, hasta el momento, «ningún sistema de IA utiliza actualmente llms.txt«. Esta declaración, aunque tajante, no ha disuadido a algunos de creer que su implementación podría ser una medida proactiva para la futura adopción de la IA, ayudando a los LLMs a representar el contenido de una empresa con mayor precisión.
De hecho, Gary Illyes, analista de Google, afirmó claramente que la compañía en la que trabaja no apoya los archivos llms.txt y no tiene planes de hacerlo. Sin embargo, la falta de un reconocimiento oficial o un uso por parte de los principales proveedores de LLMs, incluyendo al mismo Google, pone en duda su relevancia inmediata. A pesar de esto, se especula que podría convertirse en un estándar emergente para desarrolladores y automatización, particularmente para gestionar datos web y minimizar el consumo de tokens.
OpenAI: Rastreo Activo de llms.txt
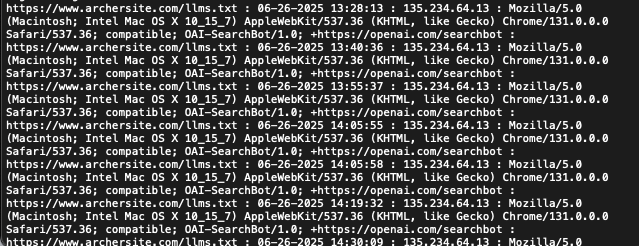
En contraste con la postura de Google, la evidencia sugiere que OpenAI, el desarrollador detrás de ChatGPT, sí está rastreando activamente los archivos llms.txt. Un usuario, de nombre Ray Martinez, compartió capturas de pantalla de sus archivos de registro, mostrando a OpenAI rastreando su archivo llms.txt aproximadamente cada 15 minutos. Este hallazgo contradice directamente la postura de Google y plantea preguntas sobre las prácticas actuales de los sistemas de IA con respecto a estos archivos.
Además de OpenAI, otras compañías notables en el espacio de la IA, como Anthropic, ElevenLabs y PineCone, tienen documentación relacionada con llms.txt, lo que indica que, a pesar del desinterés de Google, este formato tiene una relevancia creciente en el ecosistema de la inteligencia artificial.
Conclusión
Creo que el futuro del llms.txt es incierto. Mientras Google mantiene una postura de no utilización, la actividad de rastreo por parte de OpenAI y el interés de otras empresas de IA sugieren que este archivo podría desempeñar un papel importante en cómo los LLMs interactúan con el contenido web en el futuro. Este contraste de enfoques entre dos de los principales actores en el campo de la IA subraya la naturaleza evolutiva y, a menudo, incierta de los estándares en el desarrollo tecnológico.
Entonces, ¿qué nos queda? Esperar y ver en qué termina esto…
Comments are closed.